プロジェクト概要
AL日本語意味解析エンジンと知識自動構築モジュールの知識構造化開発プロジェクトです。
知識構造化プロジェクト
【話題のテキスト構造処理法】
□文書や会話などのテキストをWord2Vecで「注目した単語の周辺単語」をベクトル化して、頻度を頼りに対数/指数関数などで正則化して「類似度や距離」で分類やクラスタリング処理(文脈解析/照応解析…)を求める手法は、昔からあった技術であるが、深層学習やビックデータ、パラレル処理が安直になった近年、これが話題になった。しかし、テキストデータを食わせれば食わせる程、精度が揺らぐ現象が出てディープラーニング法を疑問に思う専門家まで現れた。
□W2Vを構成している単語の「意味概念ベクトル」であるが、ユークリッド空間上では高次元(200次元~)のベクトルでなければ精度の高い「意味概念構造」を表現できないと思われていたが、それをあっさり非ユークリッド空間の「双曲空間」で低次元(5次元程度)のベクトルだけで精度の高い意味概念構造をWordNetを使って表現できることを示した発表があった。これはPoincaré DiskやLorentz Modelへの埋め込みでのことで、理論的にも技術的にも未成熟の感があるが、今後のAI_NLU分野の新理論/技術の方向性を示したことは大きい。これからの意味概念空間モデルや知識構造化モデルなどは、ディープラーニングDeep Learningの中に双曲幾何学Hyperbolic Geometricや位相幾何学Topology、層CategoryやコホモロジーCohomologyなどの手法を取り込むのが主流になるでしょう。
【意味概念空間は曲がっている】
□そもそも類似性や意味的距離とは意味の概念空間上でのことで、単語間や文間の意味的距離を単語ベクトルや文ベクトルなどで距離を測ることが、本当に「最短距離」なのか?ベクトル間の内積などを使って距離を算出する法は、メルカルト図法で作成された世界地図(緯度と経度が座標)のようなユークリッド空間での「直線」を最短距離としていることと等価である。しかし、意味概念空間は三角形の内角の和が180度にならない、直線が最短距離にならない曲がった空間であることは、ビッグデータ処理でも精度が出ないことなどで判ってきた。例えば、東京からロサンゼルスまでの最短航路は世界地図(緯度、経度図)上の直線にはならない。地球の中心と東京、ロサンゼルスの三角平面で地球を切ったときにできる「曲がった航路」(測地線という)が最短距離(最短線という)になる。単語間や文間の類似度や意味的距離を測るにも、曲がった空間「非ユークリッド空間」である意味概念空間上で算出することが精度を向上することになる。ちなみに精度82%~92%では製品検証に不合格になる。98%以上が合格といえる。
【曲がり具合という曲率】
□テキストを言語空間(ユークリッド空間)から意味概念空間(非ユークリッド空間)への写像や埋め込み処理などをして、曲がった空間上で類似度や距離を測ることが必要になってきた。では、どこがどのくらい曲がっているのかを調べなくてはならない。結論だけをいうと局所的な曲がり具合(曲率という)は、曲面上の曲線の二次導関数を分割した法曲率ベクトルと測地的曲率ベクトルで測れる。大局的な曲率は、直截線を使った「ガウス曲率」で求めることができ、これは第一基本量Ⅰと第二基本量Ⅱという2次実対称行列Ⅰ-1Ⅱの固有値が主曲率になっているので便利である。三角形に対するガウス-ボンネの定理とは、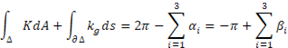
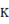 により、楕円型非ユークリッド幾何では内角の和が180度より大きくなったり、双曲型非ユークリッド幾何では小さくなったりする。そして、主曲率は、
により、楕円型非ユークリッド幾何では内角の和が180度より大きくなったり、双曲型非ユークリッド幾何では小さくなったりする。そして、主曲率は、
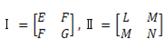 で、
で、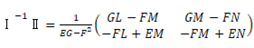 になる。
になる。
この平均曲率は  として定義され、固有値は
として定義され、固有値は 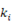 になる。
になる。
【曲がった空間のモノサシ】
□曲率が判れば、曲がった空間で距離などを測る際の基準となるモノサシ(定規)が必要である。曲がった空間へ「計量」というモノサシを入れる。フビニスタディ計量やポアンカレ計量などがあるが、ここでは接空間上の内積である「リーマン計量」を入れる。その理由は、上記の基本量Ⅰ、Ⅱという簡単な曲面上の接ベクトルの長さだけで、曲面の曲がり方が判るという「ガウスの驚愕定理」に由来する。すると、リーマン多様体(文書のこと:リーマン計量が入った空間だからリーマン多様体になった)の各点で距離が測れることになる。
【双曲空間モデルでスッキリ】
□しかし、手に入るテキストデータは限られた量なので、偏りやゴミなどが混じっている。
そこでスパース性を解消するパラメトリック法も考慮して、「曲がった空間」を「双曲空間」Hyperbolic spaceにするのはごく自然なことである。従って、リーマン計量の双曲空間版である「双曲計量」に拡張し、少ないテキストデータでも精度の高い類似度や距離が測れるようになる。ユークリッド空間の内積は 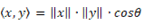 であったが、Hyperbolicの内積は
であったが、Hyperbolicの内積は 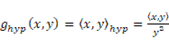 となる。曲線
となる。曲線 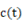 の長さは、
の長さは、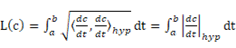 となる。
となる。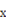 軸に近づくほど内積は大きくなるので下位概念構造は無限大になり、狭かったユークリッド空間よりも広々と表現が可能になる。これが「リーマン計量」と言われるもので、アインシュタインの特殊相対性理論でミンコフスキー空間の双曲面定義にも使われている。
軸に近づくほど内積は大きくなるので下位概念構造は無限大になり、狭かったユークリッド空間よりも広々と表現が可能になる。これが「リーマン計量」と言われるもので、アインシュタインの特殊相対性理論でミンコフスキー空間の双曲面定義にも使われている。
□双曲面から立体射影法やケーリー変換などを使って開円板やポアンカレ円板へ射影して測地線を得ることができる。
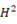 の計量
の計量 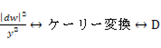 上の計量
上の計量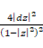 へ変換が簡単にできるので、測地線も上記の式で簡単に求めることができる。
へ変換が簡単にできるので、測地線も上記の式で簡単に求めることができる。
【シソーラス/知識構造化が簡単】
□双曲空間は木構造を自然に表現する性質を持っていることがメリットである。木構造の下位構造を無限に広げることができる。すなわち、リーマン計量や双曲空間を使えば、単語シソーラスや知識構造化が低次元ベクトルで精度良く表現できる。意味概念空間内の単語ベクトル(分布)は、ノードどうしの接続を許す複雑な「木構造」になっている。簡単な二分木でも 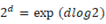 個のように指数的に増える下位ノードを持つ構造を双曲面への埋め込みで比較的簡単に表現できる。では、何故低次元ベクトルで精度良く表現できるのかは、リーマン計量の「ノルム」を使うことがカギになるのだが、まず上位語や上位概念語がベクトルに含まれていなければならない。注目される単語をポアンカレ円板の中心とした場合、この単語をトピックや話題の語彙を原点としてその周辺の単語のノルムの計算に同義性/類義性/関連性の情報が必要になる。低次元でまとめるテクニックは、これらの情報を有向非巡回グラフ的なベクトル化が必要になってくる。
個のように指数的に増える下位ノードを持つ構造を双曲面への埋め込みで比較的簡単に表現できる。では、何故低次元ベクトルで精度良く表現できるのかは、リーマン計量の「ノルム」を使うことがカギになるのだが、まず上位語や上位概念語がベクトルに含まれていなければならない。注目される単語をポアンカレ円板の中心とした場合、この単語をトピックや話題の語彙を原点としてその周辺の単語のノルムの計算に同義性/類義性/関連性の情報が必要になる。低次元でまとめるテクニックは、これらの情報を有向非巡回グラフ的なベクトル化が必要になってくる。
【知識生成とは…】
□最後に文書から知識を生成したり、上位概念を抽出するにはどうするか…。テキスト群を意味概念空間へ写像して「曲がった行列」で表現された「半正定値非対称行列」にリー群でエイシックリックな構造を入れてから加群の知識を抽出していくことになる。有向非巡回グラフは、この行列から表現できるので、ここから知識の候補を生成していく。そして商空間(剰余)でイデアルを抽出して、視点View Point別な独立な知識を生成していく。この処理をディープラーニングで行うことが重要である。位相空間の族や近傍系、閉集合系、閉包作用素を使ったり、文の完全系列や圏論の関手での切断(section)による茎(stalks)や芽(germs)での視点を見極めていくことになる。最小知識はsimplex、その複合知識はcomplexになり、これらの知識の連結を創って上位概念や上位語を生成していく。
NLP-数理モデル比較表
|
NLPモデル |
解析項目 |
数理モデル |
例文 |
|
|
|||
|
最長一致法 字種結合 |
分ち書き Chunking |
N-gram、ベイズ定理 Latticeアルゴリズム DP(動的計画法) CRF(条件付き確率場) HMM(隠れマルコフ) VA(ビタビアルゴリズム) 有限オートマトン… |
太郎/は/会社/へ/行っ/た/。 彼/は/5G/の/スマホ/を/買/った/。 |
|
助詞探索法 品詞列文法 文法依存法 |
品詞付与 基本品詞 詳細品詞 活用型 活用形 |
太郎(名詞)は(助詞)会社(名詞)へ(助詞)行っ(動詞)た(助動詞)。(記号) 彼(人称代名詞)は(助詞)5G(未知語;名詞)の(助詞)スマホ(名詞)を(助詞)買(動詞)った(助動詞)。(記号) |
|
|
辞書 品詞文法 |
基本言語処理 |
線形代数 統計学、確率論 |
有償・無償の形態素解析ソフト多々 品詞種の相違が特徴になっている |
|
|
|||
|
文脈自由文法 句構造文法 |
連文節統合 文節結合 |
カーネル法 Polynominal kernel 多項式モデル 系列モデル… |
主部((大きな)主語(太郎は))修飾部(修飾語(会社へ))述部((すぐに)述語(行った)) |
|
LFG GPSG |
係り受け付与 |
SP主述(太郎は,行った) MP修述(会社へ,行った) |
|
|
国文法に依る処理系 |
形態素解析+構文解析=統語解析Parse |
解析幾何学 微分幾何学 |
構文解析ソフトは数が少ない 精度に問題が残る |
|
|
|||
|
談話表示理論 |
照応付与 |
HMM、ベイズの定理 Kalman’s filter Attention(BERT) Transformers… |
彼(太郎)はそこ(会社)で会議をした。 |
|
概念依存論 |
共参照付与 |
そこ(会社=意味研㈱) |
|
|
シャンク概念 |
結束性付与 |
会議(原因=コロナ休暇)因果関係 |
|
|
フレーム意味 |
結束構造 |
会議(∈会社)包含関係 |
|
|
意味概念論に依る処理系 |
文の意味解釈には重要なファクター |
微分幾何学 線形代数 |
文脈解析ソフトはほとんどない 世界中が研究中である |
|
|
|||
|
カテゴリー文法 語用論 |
概念タグ付与 固有表現 |
Clusetring Classification… |
太郎=固有名詞∈人名⊂人間 会社=組織∈機能 |
|
格文法 概念依存文法 |
意味タグ付与 意図タグ付与 |
Heuristic method … |
AgentMoveOrg(太郎行った会社) AgentDiscuss(topic)(参加者?会議) |
|
カテゴリーや概念に依る処理系 |
アプリ用タグ |
線形代数 ユークリッド空間 凸系近傍処理 |
Googleなど世界中でトライ中 スマートスピーカーやChatbotなどのアプリの命令系に使う意味タグ |
|
|
|||
|
モンタギュ文法 述語論理 |
知識生成 |
半正定値対称行列 … |
地球は太陽を中心に公転している。 地球は地軸を中心に自転している。 |
|
様相論理 |
知識構造化 |
意味概念包含 双曲幾何学 |
KE1⊂KE2、KE3∈KE4 |
|
記号論理学 |
知識推論 |
組合せ最適化 |
newKE←Inference(KE5、KE6) |
|
論理系 形式論理学 |
NLPの最終目的 知識構造体 |
組合せ論 微分幾何学 |
クラウドに全ての分野の専門知識をアップして自動更新 |
|
|
|||
|
空間認知 状況表現
|
クラスタリングClustering |
凝集型 k-平均法 混合正規分布 EMアルゴリズム… |
Sim(疫病、新型コロナウイルス) ユークリッド空間 ベクトル空間上での類似や距離 |
|
概念依存法
|
分類 Classification |
ナイーブベイズ SVM カーネル法 対数線形モモデル … |
CF(品詞|単語) CF(ジャンル|文書) 同型 同相 |
|
シーン表現 |
トピック抽出 |
トピックモデル |
Vtopic_viewpoint(トピック|文書) |
|
概念構造 |
要約生成 |
特徴抽出モデル TF-IDF |
「ズバリ要約」「SP-Summary」 抄録、ダイジェスト、アブストラクト |
|
概念構造 |
分類系 |
統計学 |
語彙系の辞書作りに活用 |
|
|
|||
|
|
素性Feature特徴 |
Heuristic method TF-IDF… |
頻度(単語|ジャンル) |
|
|
スパース性 |
線形回帰、Lasso ℓ1ノルム… |
|
|
|
連続性と離散性 |
多様体論… |
|
|
|
汎化性と近似 |
深層学習 直交補空間… |
|
|
|
相関性と類義性 |
情報幾何学… |
|
|
|
階層化シソーラス Ontology |
Poincare embeddings Lorentzモデル… |
|
|
|
有向非巡回グラフ |
層、コホモロジー |
|
|
|
|
|
|
AL日本語意味解析エンジンは、
- 形態素解析(分ち書き+品詞付け+概念タグ付与)
概念タグは固有表現を詳細化、階層化(数千種類)されたタグ - 構文解析(連文節文節間の係受関係と関係子付与)
関係子は独自の構文関係子 - 文脈解析(照応解析:代名詞代入とゼロ代名詞補完)
(ゼロ)照応詞と先行詞(形態素∈文節⊂連文節⊂文)の特定 - 意味解析(意味タグ付与)
全ての係受関係子へ意図を明示化する意味タグ付与
知識自動構築モジュールは、
- 知識生成モジュール
文書から独立な知識を生成する
拡張された意味フレーム - 知識構築モジュール
知識の上下階層化(包含関係)
知識の因果関係(従属関係) - 新知識推論モジュール
既存知識構造から仮説検証で新知識の生成